The following include some scenarios in which removing whitespaces might be necessary:
- To reformat source code
- To clean up data
- To simplify command-line outputs
It is possible to remove whitespaces manually if a file that contains only a few lines. But, for a file containing hundreds of lines, then it will be difficult to remove all the whitespaces manually. There are various command-line tools available for this purpose, including sed, awk, cut, and tr. Among these tools, awk is one of the most powerful commands.
What Is Awk?
Awk is a powerful and useful scripting language used in text manipulation and report generation. The awk command is abbreviated using the initials each of the people (Aho, Weinberger, and Kernighan) who developed it. Awk allows you to define variables, numeric functions, strings, and arithmetic operators; create formatted reports; and more.
This article explains the usage of the awk command for trimming whitespaces. After reading this article, you will learn how to use the awk command to perform the following:
- Trim all whitespaces in a file
- Trim leading whitespaces
- Trim trailing whitespaces
- Trim both leading and trailing whitespaces
- Replace multi spaces with a single space
The commands in this article were performed on an Ubuntu 20.04 Focal Fossa system. However, the same commands can also be performed on other Linux distributions. We will use the default Ubuntu Terminal application for running the commands in this article. You can access the terminal using the Ctrl+Alt+T keyboard shortcut.
For demonstration purposes, we will use the sample file named “sample.txt.” to perform the examples provided in this article.
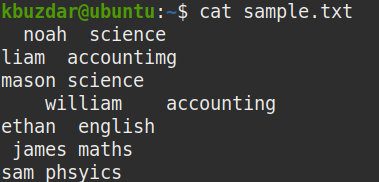
View All Whitespaces in a File
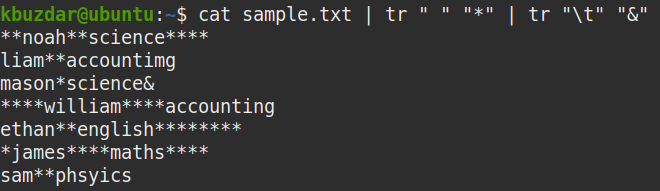
To view all the whitespaces present in a file, pipe the output of the cat command to the tr command, as follows:
This command will replace all the whitespaces in the given file with the (*) character. After entering this command, you will be able to see clearly where all the whitespaces (including both leading and trailing whitespaces) are present in the file.
The * characters in the following screenshot show where all the whitespaces are present in the sample file. A single * represents single whitespace.
Trim All Whitespaces
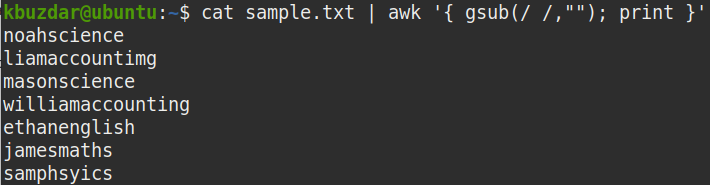
To remove all the whitespaces from a file, pipe the out of cat command to the awk command, as follows:
Where
- gsub (stands for global substitution) is a substitution function
- / / represent white space
- “” represents nothing (trim the string)
The above command replaces all whitespaces (/ /) with nothing (“”).
In the following screenshot, you can see that all the whitespaces, including the leading and trailing whitespaces, have been removed from the output.
Trim Leading Whitespaces
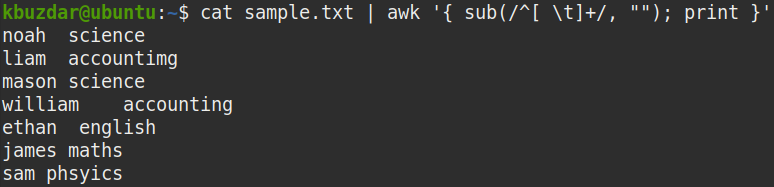
To remove only the leading whitespaces from the file, pipe the out of cat command to the awk command, as follows:
Where
- sub is a substitution function
- ^ represents the beginning of the string
- [ \t]+ represents one or more spaces
- “” represents nothing (trim the string)
The above command replaces one or more spaces at the beginning of the string (^[ \t]+ ) with nothing (“”) to remove the leading whitespaces.
In the following screenshot, you can see that all the leading whitespaces have been removed from the output.
You can use the following command to verify that the above command has removed the leading whitespaces:
tr "\t" "&"
In the screenshot below, it is clearly visible that only the leading whitespaces have been removed.
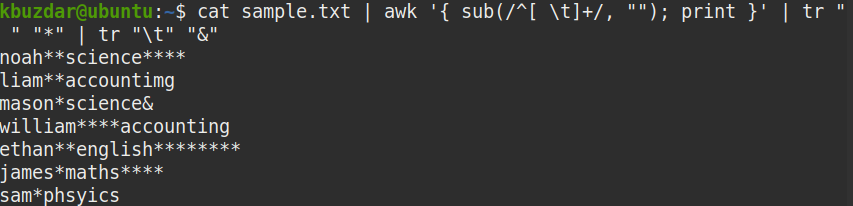
Trim Trailing Whitespaces
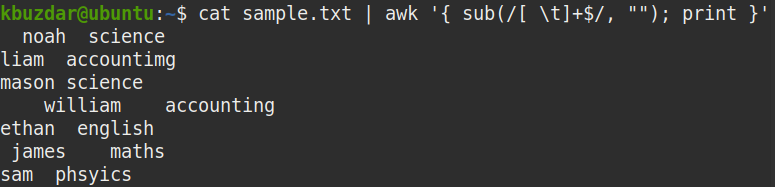
To remove only the trailing whitespaces from a file, pipe the out of cat command to the awk command, as follows:
Where
- sub is a substitution function
- [ \t]+ represents one or more spaces
- $ represents the end of the string
- “” represents nothing (trim the string)
The above command replaces one or more spaces at the end of the string ([ \t]+ $) with nothing ( “”) to remove the trailing whitespaces.
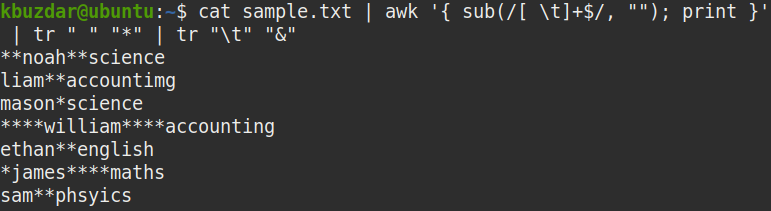
You can use the following command to verify that the above command has removed the trailing whitespaces:
From the below screenshot, it is clearly visible that the trailing whitespaces have been removed.
Trim Both Leading and Trailing Whitespaces
To remove both the leading and trailing whitespaces from a file, pipe the out of cat command to the awk command, as follows:
Where
- gsub is a global substitution function
- ^[ \t]+ represents leading whitespaces
- [ \t]+$ represents trailing whitespaces
- “” represents nothing (trim the string)
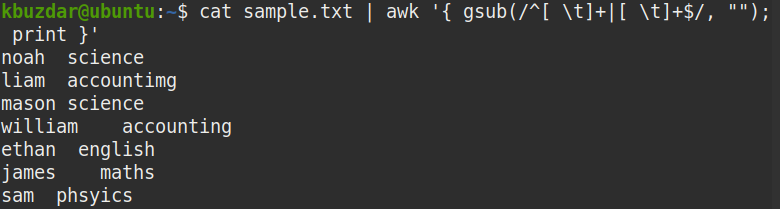
The above command replaces both the leading and trailing spaces (^[ \t]+ [ \t]+$) with nothing (“”) to remove them.
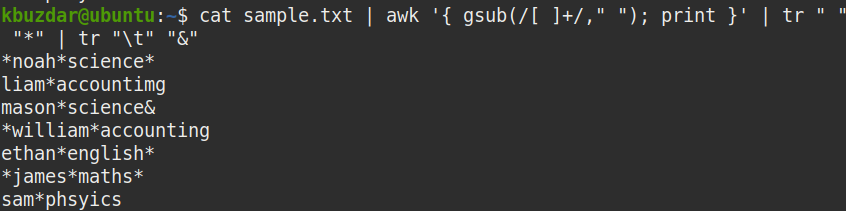
To determine whether the above command has removed both the leading and trailing whitespaces in the file, use the following command:
tr " " "*" | tr "\t" "&"
From the below screenshot, it is clearly visible that both the leading and trailing whitespaces have been removed, and only the whitespaces between the strings remain.

Replace Multiple Spaces with Single Space
To replace multiple spaces with a single space, pipe the out of cat command to the awk command, as follows:
Where:
- gsub is a global substitution function
- [ ]+ represents one or more whitespaces
- “ ” represents one white space
The above command replaces multiple whitespaces ([ ]+) with a single white space (“ “).
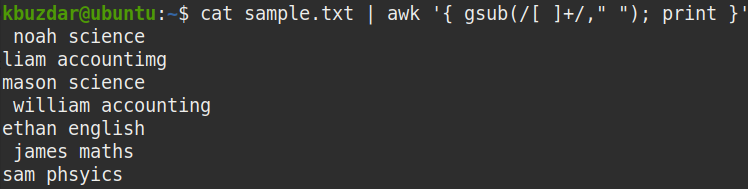
You can use the following command to verify that the above command has replaced the multiple spaces with the whitespaces:
There were multiple spaces in our sample file. As you can see, multiple whitespaces in the sample.txt file were replaced with a single white space by using the awk command.
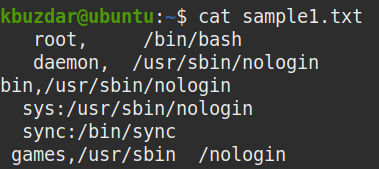
To trim the whitespaces in only those lines that contain a specific character, such as a comma, colon, or semi-colon, use the awk command with the -F input separator.
For instance, shown below is our sample file that contains whitespaces in each line.
To remove the whitespaces from only the lines that contain a comma (,), the command would be as follows:
Where (-F,) is the input field separator.
The above command will only remove and display the whitespaces from the lines that contain the specified character (,) in them. The rest of the lines will remain unaffected.

Conclusion
That is all you need to know to trim the whitespaces in your data using the awk command. Removing the whitespaces from your data may be required for several different reasons. Whatever the reason is, you can easily trim all the whitespaces in your data using the commands described in this article. You can even trim leading or trailing whitespaces, trim both leading and trailing whitespaces, and replace multi spaces with a single space with the awk command.